第1章:微处理器性能的过去、现在与未来
Table of Contents
这是一个关于编写高性能代码的workshop。在其他workshop中,我会讨论解耦设计和可维护性,但今天我们要讨论的是性能。
我想以一个简短的讲座开始今天的内容,讲讲我如何看待计算机演进的历史,以及为什么我认为编写高性能软件很重要。
现实是软件运行在硬件上,所以要讨论编写高性能代码,首先我们需要讨论运行我们代码的硬件。
1.1 Mechanical Sympathy(机械同理心)

目前流行的一个术语是"mechanical sympathy",你会听到Martin Thompson或Bill Kennedy等人谈论它。
“Mechanical Sympathy"这个名字来自伟大的赛车手Jackie Stewart,他是三届F1世界冠军。他相信最优秀的车手对机器的工作原理有足够的理解,能够与之和谐共处。
要成为一名伟大的赛车手,你不需要成为一名伟大的机械师,但你需要对汽车的工作原理有超过表面的理解。
我认为编程也是如此。
1.2 六个数量级(Six orders of magnitude)

来源:Jeff Preshing, Leap seconds are a hack
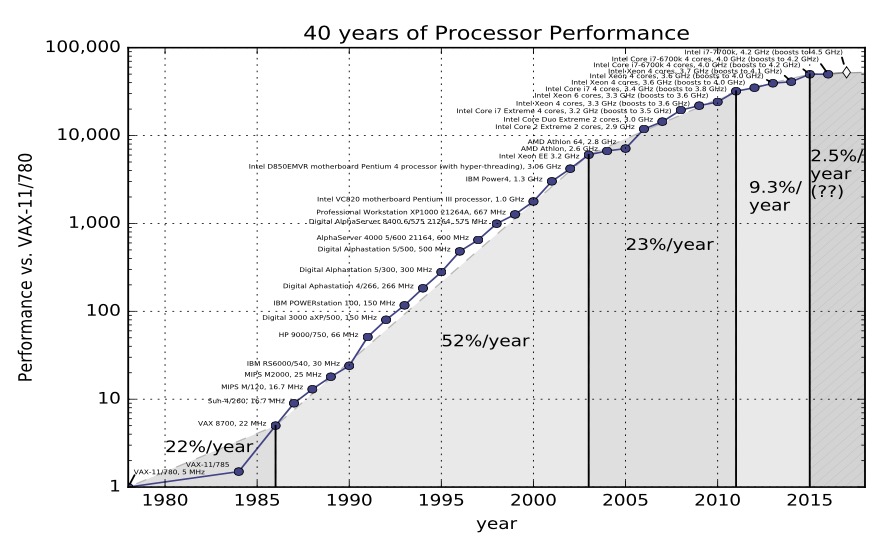
这张图显示了从1970年代到2010年代微处理器性能的增长情况。
注意这是对数刻度;在30年间,性能提升了6个数量级。
从1970年代中期,每18个月性能就会翻倍。这是一个令人难以置信的连续改进期,在任何工程学科中都是前所未有的。
但你会注意到,这些数据只到2015年就停止了。今天的最快处理器与2015年没有太大区别。
1.3 计算机还在变快吗?
让我们来看几张图表:
时钟频率(Clock Speed)
来源:Herb Sutter, The Free Lunch Is Over
这张图显示了从1970年到2010年的CPU时钟频率。
你可以看到,从2004年左右开始,时钟频率就停止增长了,实际上略有下降。
为什么?
我们来看另一张图:
1.4 时钟频率
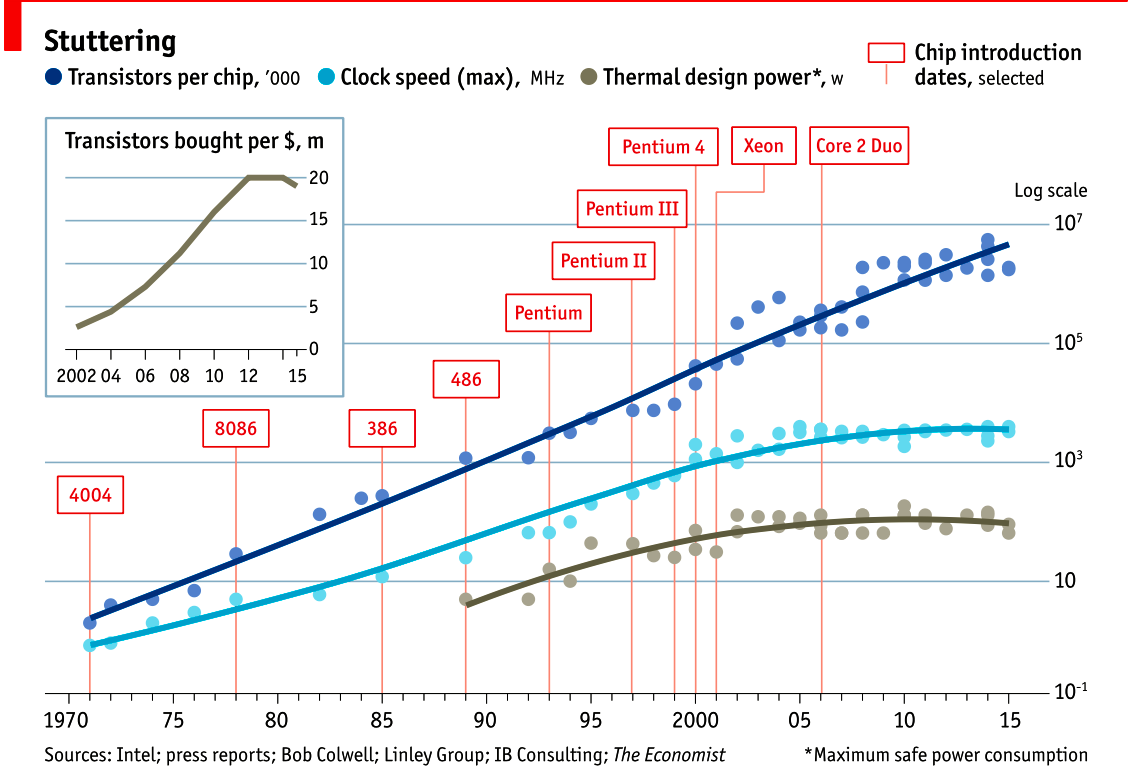
为什么时钟频率停止增长?CPU制造商说他们已经达到了"功率墙”(power wall)。
来源:The Future of Microprocessors, Sophie Wilson
这张图是Sophie Wilson从一些旧的Intel数据表中绘制的。
它显示了Intel处理器的功耗(纵轴)与时钟频率(横轴)的关系。
你可以看到,在2GHz左右,功耗开始指数级增长。
1.5 热量(Heat)
来源:Patrick Gelsinger, Managing Technology, IDF Spring 2004
这张著名的图表比较了CPU的功率密度(每平方厘米的瓦数)与其他物体。
关键观察:
- 热板:~10 W/cm²
- 核反应堆:~50 W/cm²
- Pentium 4:~100 W/cm²
- 太阳表面:~6000 W/cm²
如果CPU时钟频率继续按照之前的趋势增长,它们的功率密度会超过太阳的表面。
显然这是不可能的。
1.6 Dennard scaling的终结
为了理解为什么,让我们谈谈Dennard scaling。
Dennard scaling(登纳德缩放比例定律):随着晶体管变小,它们的功率密度保持不变。因此,即使晶体管缩小,它们使用的功率也按比例减少。
Robert H. Dennard在1974年观察到了这一点。
然而,在2006年左右,Dennard scaling停止了。晶体管继续变小,但它们的功率密度不再保持不变。这是因为:
- 漏电流(leakage current)变得严重
- 晶体管即使在"关闭"状态也会消耗电力
这意味着虽然晶体管变小了,但它们不再变得更省电。
1.7 更多核心(More cores)
来源:The Free Lunch Is Over, Herb Sutter
CPU制造商不能再提高时钟频率,所以他们开始增加更多的核心。
这张图显示:
- 单核时代结束于2005年左右
- 之后是双核、四核、八核…
问题是: 你的程序准备好利用多核了吗?
1.8 Amdahl定律(Amdahl’s Law)

Amdahl定律描述了程序并行化的理论加速比上限。
公式:
加速比 = 1 / (S + P/N)
其中:
S = 程序中必须串行执行的部分(不能并行)
P = 可以并行执行的部分
N = 处理器核心数
例子: 如果你的程序有10%必须串行执行(S=0.1),90%可以并行(P=0.9):
| 核心数 | 加速比 |
|---|---|
| 1 | 1.0x |
| 2 | 1.8x |
| 4 | 3.1x |
| 8 | 4.7x |
| 16 | 6.4x |
| 32 | 7.5x |
| ∞ | 10.0x (理论上限) |
关键启示: 即使有无限个CPU核心,10%的串行代码也会限制最大加速比为10倍。
**Universal Scalability Law(通用可扩展性定律)**更进一步,考虑了核心之间的协调开销(如锁、缓存一致性)。
1.9 动态优化(Dynamic Optimisations)
现代CPU包含大量的动态优化技术:
- 分支预测(Branch Prediction):预测代码将走哪个分支
- 推测执行(Speculative Execution):提前执行代码,如果预测错误则丢弃
- 乱序执行(Out-of-Order Execution):重新排列指令以更好地利用CPU资源
这些优化使CPU能够在时钟频率停滞的情况下继续提高性能。
但是:
- 这些优化增加了CPU的复杂性
- 增加了功耗
- 有时会导致安全漏洞(如Spectre/Meltdown)
1.10 现代CPU针对批量操作进行了优化
现代CPU不是针对单个操作的速度进行优化,而是针对批量操作的吞吐量。
SIMD(Single Instruction Multiple Data):
- 一条指令同时处理多个数据
- 例如:同时对8个数字进行加法
向量化(Vectorization):
- 编译器将循环转换为SIMD指令
- 可以显著提高性能
启示:
- 连续的、可预测的数据访问模式性能最好
- 随机访问、分支密集的代码性能较差
1.11 现代处理器受限于内存延迟而非内存容量
在过去,性能受限于内存容量。今天,性能受限于内存延迟。
延迟数字(Peter Norvig,2020更新):
| 操作 | 延迟 | 注释 |
|---|---|---|
| L1 cache引用 | 0.5 ns | |
| 分支预测错误 | 5 ns | |
| L2 cache引用 | 7 ns | L1引用的14倍 |
| 互斥锁加锁/解锁 | 25 ns | |
| 主内存引用 | 100 ns | L1引用的200倍 |
| 用Zippy压缩1KB | 3,000 ns | 3 µs |
| 通过1 Gbps网络发送2KB | 20,000 ns | 20 µs |
| SSD随机读 | 150,000 ns | 150 µs |
| 从SSD顺序读1MB | 1,000,000 ns | 1 ms |
| 磁盘寻道 | 10,000,000 ns | 10 ms |
| 从磁盘顺序读1MB | 20,000,000 ns | 20 ms |
| 数据包往返加州-荷兰-加州 | 150,000,000 ns | 150 ms |
关键观察:
- 主内存访问比L1 cache慢200倍
- 一次主内存访问,CPU可能空等200个周期
- 在这200个周期里,CPU本可以执行数百条指令
启示: 编写高性能代码的关键不是做更少的工作,而是减少内存访问。
1.12 缓存规则一切(Cache rules everything around me)
现代CPU有多级缓存:
CPU Core
|
[L1 Cache] - 32-64KB,~0.5ns
|
[L2 Cache] - 256KB-1MB,~7ns
|
[L3 Cache] - 8-32MB,~40ns(多核共享)
|
[主内存(RAM)] - GB级,~100ns
缓存行(Cache Line):
- CPU不是按字节加载数据,而是按缓存行
- 现代CPU的缓存行大小通常是64字节
示例:
const CacheLineSize = 64 // bytes
type Example struct {
a int64 // 8 bytes
b int64 // 8 bytes
// ...
}
// 读取a时,整个64字节的缓存行都会被加载
// 如果接下来读取b,它可能已经在缓存中了
False Sharing(伪共享):
当多个CPU核心修改同一缓存行中的不同变量时,会导致严重的性能问题:
// 问题代码
type BadCounter struct {
counter1 int64 // goroutine 1修改
counter2 int64 // goroutine 2修改
}
// counter1和counter2在同一个64字节缓存行中
// 每次修改都会使其他核心的缓存行失效
// 解决方案:缓存行填充
type GoodCounter struct {
counter1 int64
_padding [56]byte // 填充到64字节
counter2 int64
}
编写缓存友好的代码:
- 顺序访问数据:
// 好:顺序访问
for i := 0; i < len(slice); i++ {
process(slice[i])
}
// 差:随机访问
for _, idx := range randomIndices {
process(slice[idx])
}
- 减少数据结构大小:
// 更小的结构 = 更多数据能放入缓存
type Compact struct {
id uint32 // 4字节够用就不用8字节
flag uint8 // 1字节够用就不用bool
}
- 数据局部性:
// 相关数据放在一起
type Order struct {
// 热数据:经常访问
id uint64
status uint8
// 冷数据:很少访问(可以放在后面)
createdAt time.Time
metadata map[string]string
}
1.13 免费的午餐结束了(The free lunch is over)
2005年,C++委员会主席Herb Sutter撰写了一篇题为《免费的午餐结束了》(The free lunch is over)的文章。
在文章中,Sutter讨论了我所涵盖的所有要点,并断言未来的程序员将无法再依赖CPU时钟速度的提升来使他们的程序运行得更快。
现在,十多年过去了,毫无疑问Herb Sutter是对的。
内存很慢,缓存太小,CPU时钟速度正在倒退,单线程CPU的简单世界已经一去不复返了。
Moore定律仍然有效,但对于我们这个房间里的所有人来说,免费的午餐已经结束了。
1.14 结论
我会引用的数字是到2010年:30GHz,100亿个晶体管,每秒1万亿条指令。 — Pat Gelsinger, Intel CTO, 2002年4月
很明显,如果材料科学没有突破,CPU性能每年增长52%的日子回归的可能性微乎其微。
普遍的共识是,问题不在于材料科学本身,而在于晶体管的使用方式。逻辑结论是,为了从硅中获得更高的性能,我们需要改变软件。
网上有很多演讲都在重复这一点。它们都有相同的预测——未来的计算机编程方式将与今天不同。一些人认为它会更像图形卡,有数百个非常简单、非常不连贯的处理器。其他人则认为超长指令字(Very Long Instruction Word,VLIW)将会复兴。
我的观点是,这些预测是正确的,硬件制造商在这一点上拯救我们的前景是黯淡的。
然而,对于我们今天编写的程序,针对我们今天拥有的硬件,有巨大的优化空间。
Rick Hudson在GopherCon 2015上谈到了重新建立"良性循环",即软件为硬件编写得更好,硬件制造商为该软件设计更好的硬件,而软件作者又利用新硬件的功能,如此循环往复。
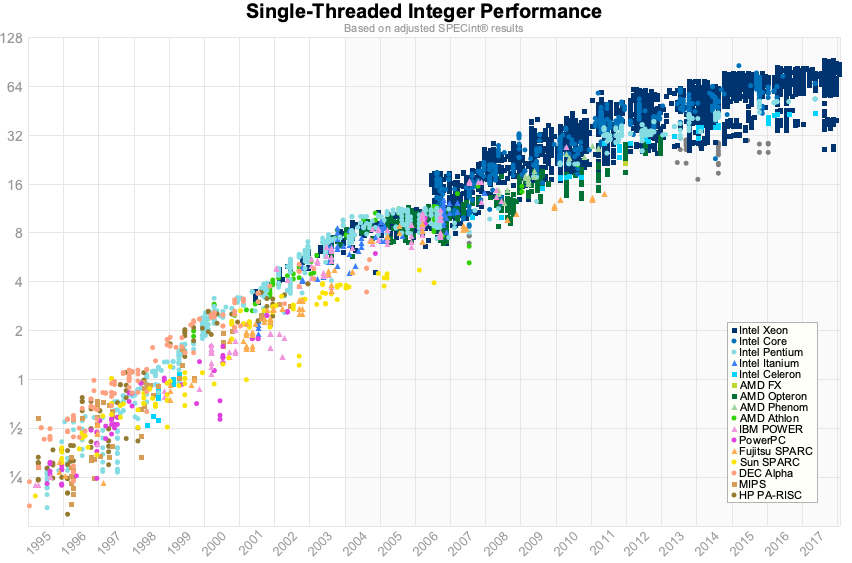
从我之前展示的图表来看,从2015年到2018年,整数性能最多提高了5-8%,内存延迟的改善甚至更少,而Go团队已经将垃圾回收器的暂停时间减少了两个数量级。
Go 1.11程序的GC延迟明显优于运行Go 1.6程序的机器,即使该机器的硬件速度提高了50%。
系列导航: