Mysql慢查询分析
·935 words·2 mins
Table of Contents
获取sql
从mybatis日志中获取sql语句,通过explain进行分析。
grep -E '==> Preparing:' bytello.log | sed 's/.*==> Preparing:/explain/' | sed 's/\($\)/;/' | sed 's/\?/""/g' | sed 's/LIMIT ""/LIMIT 5/' | sort -u | uniq > test.txt
稍微解释一下,怕以后忘了。 grep -E ‘==> Preparing:’ bytello.log 是通过正则匹配包含’==> Preparing:‘的行。 然后通过管道将每一行的结果输出到下一个命令。 sed ’s/.==> Preparing:/explain/’ 是将.==> Preparing替换成expalin。(熟悉一下sed的语法就行) 后面的sed含义类似。 sort -u | uniq 是去除重复行。 最后输出到test.txt
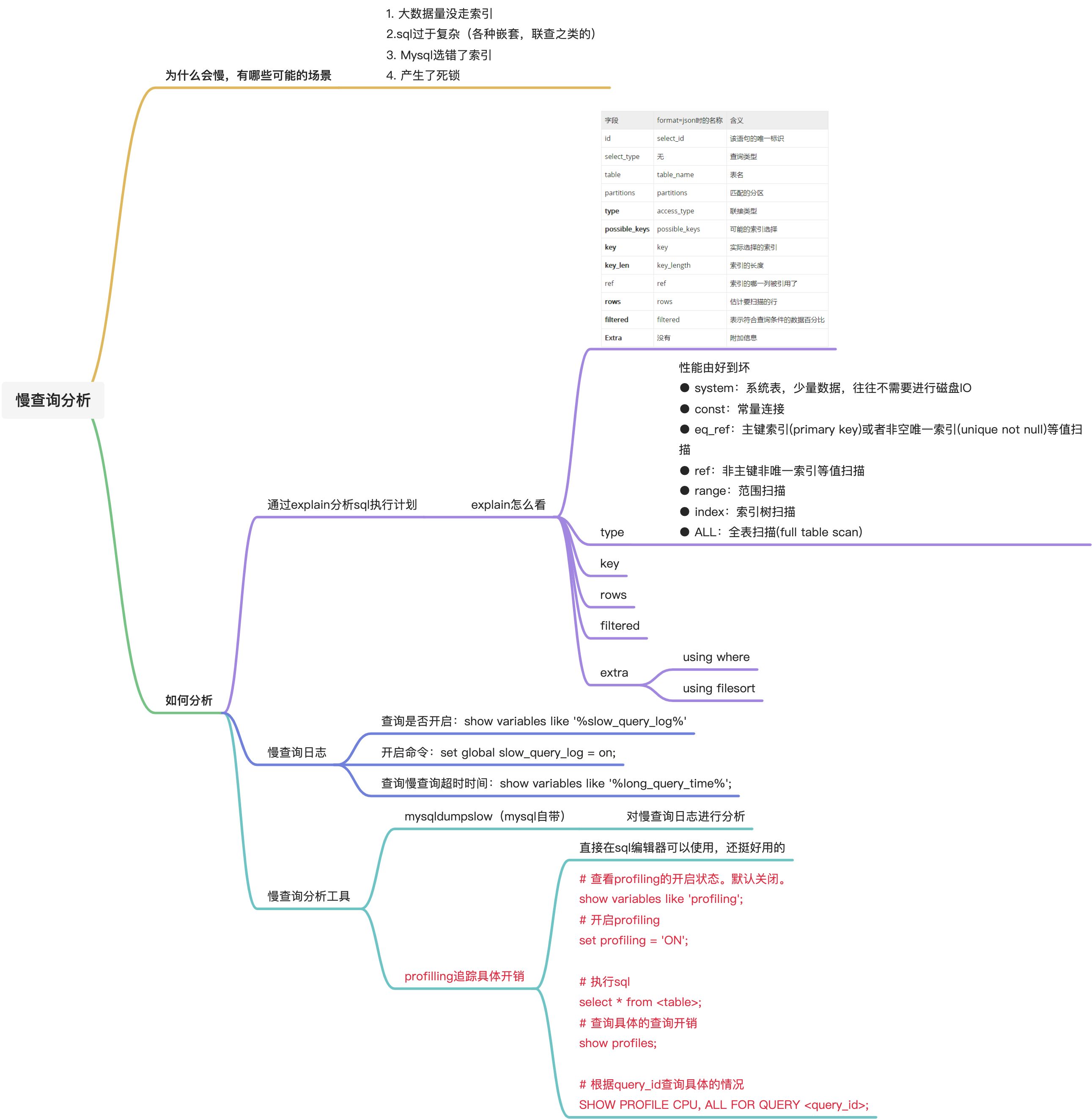
explain
type含义
性能由好到坏
- system:系统表,少量数据,往往不需要进行磁盘IO
- const:常量连接
- eq_ref:主键索引(primary key)或者非空唯一索引(unique not null)等值扫描
- ref:非主键非唯一索引等值扫描
- range:范围扫描
- index:索引树扫描
- ALL:全表扫描(full table scan)
explain确实可以分析,但是sql太多了,难道一行一行看嘛。我们可是程序员。不能干这种事吧。 应该会有一些工具帮助我们做这些事的。
通过慢查询日志分析
查看数据库是否开启慢查询,以及慢查询日志存放位置。
show variables like ‘%slow_query_log%’;
- slow_query_log //是否开启,默认关闭,建议调优时才开启
- slow_query_log_file //慢查询日志存放目录
开启慢查询
set global slow_query_log = on;
查询慢查询时间,默认是10s,但是测试推荐设置0。因为代价不高,然后方便分析。
**show **variables **like **’%long_query_time%’;
慢查询测试 select sleep(11);
慢查询分析工具
mysqldumpslow (mysql自带)
常用命令
得到返回记录集最多的10条SQL:
mysqldumpslow -s r -t 10 /var/lib/mysql/mysql-slow.log
得到访问次数最多的10条SQL:
mysqldumpslow -s r -t 10 /var/lib/mysql/mysql-slow.log
得到按照时间排序的前10条里面含有左连接的SQL:
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/mysql-slow.log
也支持管道符命令
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/mysql-slow.log | more //分页显示
pt-query-digest (percona-toolkit中的产品)
通过profilling来追踪具体的查询开销
# 查看profiling的开启状态。默认关闭。
show variables like 'profiling';
# 开启profiling
set profiling = 'ON';
# 执行sql
select * from <table>;
# 查询具体的查询开销
show profiles;
# 根据query_id查询具体的情况
SHOW PROFILE CPU, ALL FOR QUERY <query_id>;
为什么会慢
可以通过mysql-slow.log来查看sql具体的执行情况【应该需要开启slowlog】
常见的慢查询场景
- 大数据量没走索引
- sql过于复杂(各种嵌套,联查之类的)
- Mysql选错了索引
- 产生了死锁