彻底搞懂synchonized
Table of Contents
CPU执行过程
我们都知道Synchonized可以保证原子性,可以保证线程的同步。那么Synchonized是怎么保证的呢。
从CPU说起,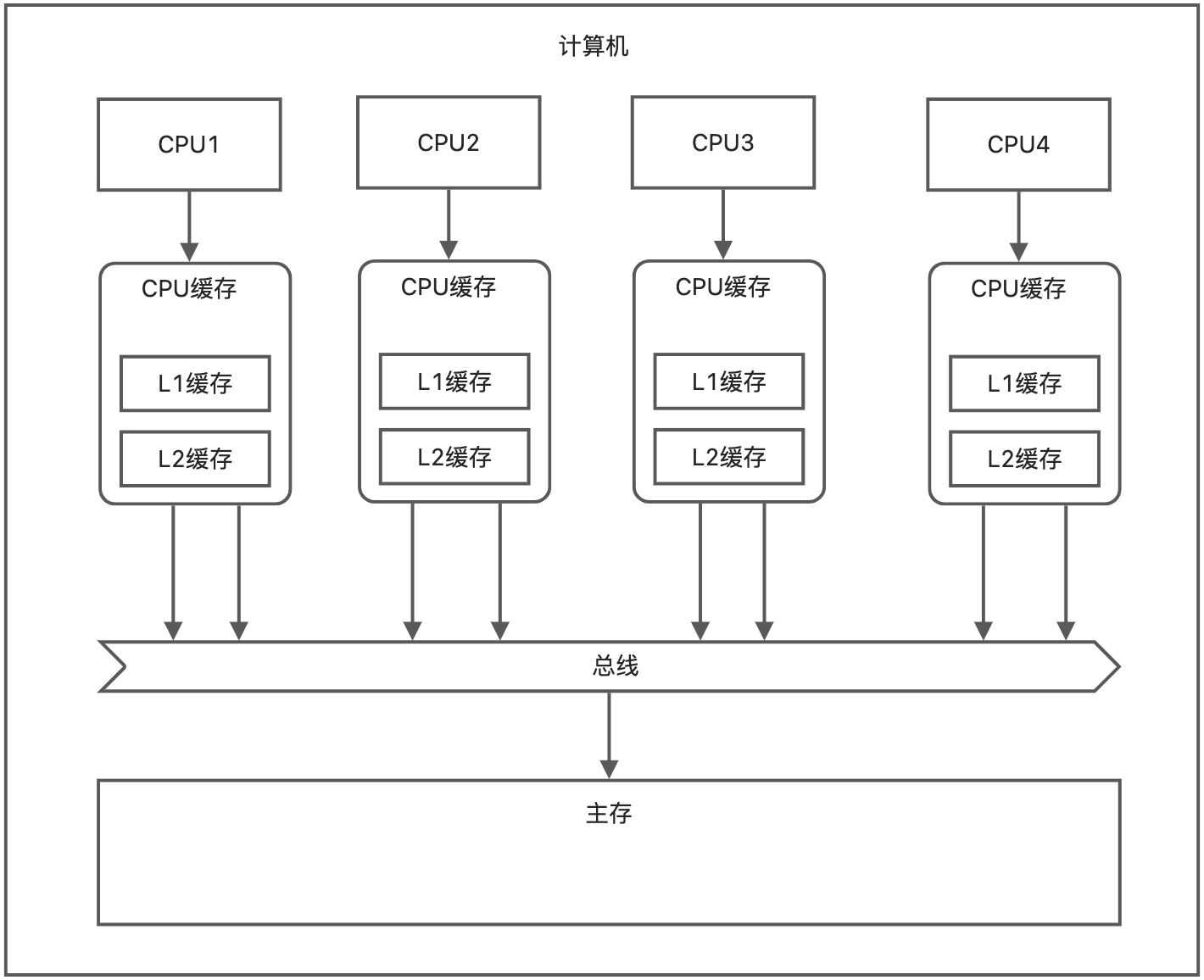
监控锁(原子性保证)
使用Synchonized关键字封装的代码块在编译成汇编语言时,会在这段代码块之前加上monitorenter关键字,之后加上monitorexit关键字。加上这两个关键字怎么就可以保证数据的同步呢?
总线锁定
当cpu执行到monitorenter时,会在总线上发出lock信号,其他cpu收到lock信号之后,就不能操作缓存和内存中的值了。所以这个代价挺高的。
缓存锁定
总线锁定封锁了缓存和主存数据的读取和修改,为了降低总线锁定的代价,有些cpu把单个值的更新优化成了缓存锁定。对于下图的场景,当CPU1修改了缓存中的值时,CPU2修改时就发现缓存锁定了,无法修改了。
- 只能针对单个缓存行的更改【缓存行:缓存的最小单位】
- 有些处理器不支持
Synchronized优化
虽然上诉过程可以在底层保证操作的原子性。但是总线锁定的成本也是很高的。而且JVM团队在实际场景中发现,出现并发的场景其实很少。 于是在JDK1.6版本就优化Synchronized的实现。主要包括锁消除,锁膨胀和锁升级的过程。
锁消除
在 synchronized 修饰的代码中,如果不存在操作临界资源的情况,会触发锁消除,你即便写了 synchronized ,他也不会触发
public synchronized void method(){
// 没有操作临界资源
// 此时这个方法的synchronized你可以认为没有
}
锁膨胀
如果一个循环中,频繁的获取和释放资源,这样的消耗很大。锁膨胀就会将锁的范围扩大,避免频繁的竞争和获取锁资源带来不必要的消耗。
public void method(){
for(int i = 0;i < 999999;i++){
synchronized(对象){
}
}
// 这是上面的代码会触发锁膨胀
synchronized(对象){
for(int i = 0;i < 999999;i++){
}
}
}
锁升级
锁状态
- 无锁状态
- 偏向锁状态
- 轻量级锁状态
- 重量级锁状态
锁升级过程
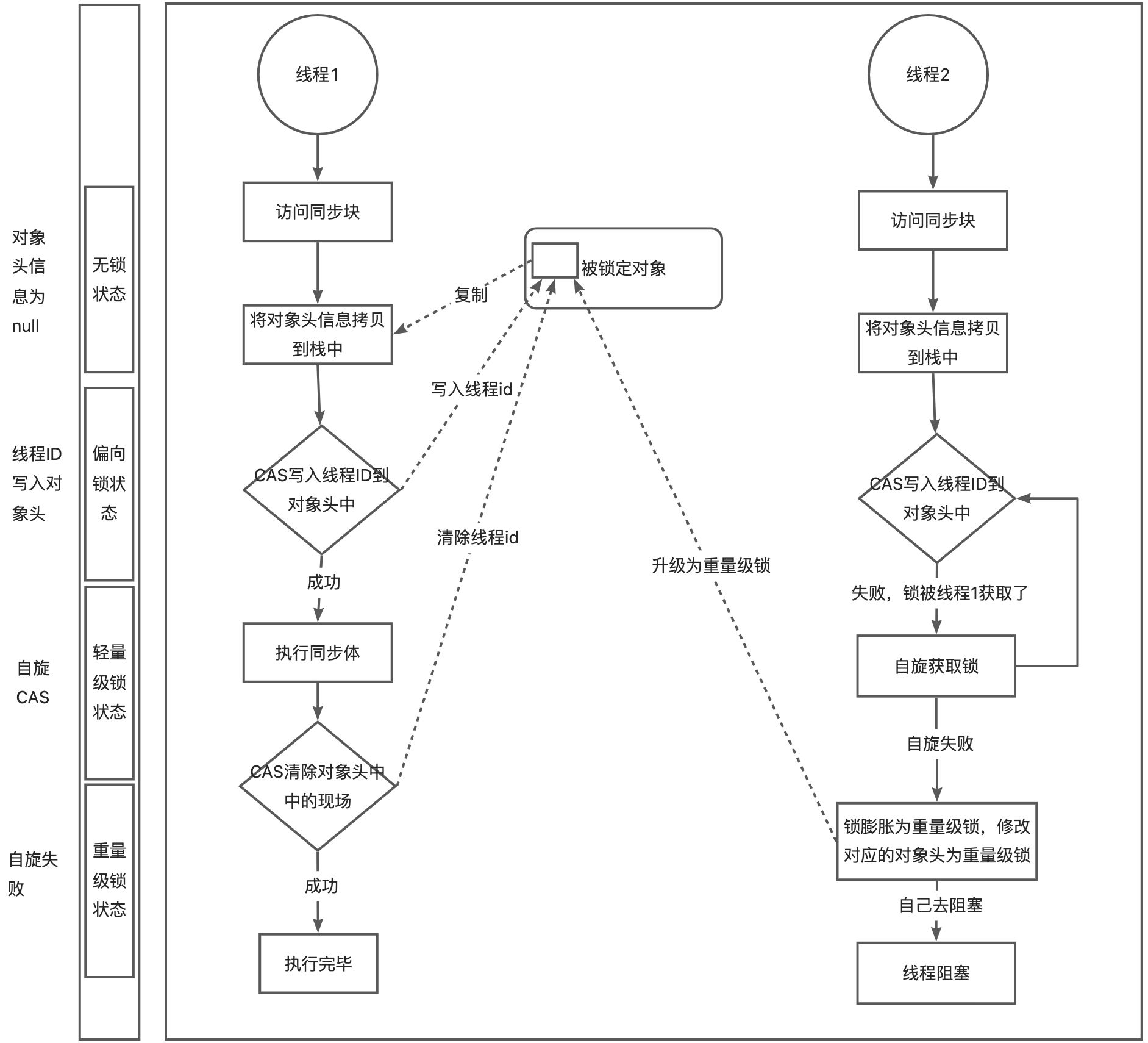

Sychronized实现原理
锁升级过程
重量级锁实现
我们知道字节码层面,synchonized关键字会增加monitorenter和monitorexit,在在jvm层面是如何实现锁的处理的呢?主要是通过ObjectMonitor来实现操作的。
ObjectMonitor处理流程
- 我们线程刚进来时,会进入 Cxq 的队列中
- 当我们的 owner 释放锁时,会将 Xcq 里面的线程放到 EntryList 中
- 这个时候由 OnDeck Thread 去进行锁竞争,竞争失败的则继续留在 EntryList 中
- 当调用 Object.wait() 会进入 _WaitSet 队列,只要被唤醒时,才会重新进入 EntryList 中
在重量级锁中没有竞争到锁的对象会 park 被挂起,退出同步块时 unpark 唤醒后续线程。唤醒操作涉及到操作系统调度会有额外的开销。
参考
https://xiaohuang.blog.csdn.net/article/details/129848342?spm=1001.2014.3001.5502 https://xiaomi-info.github.io/2020/03/24/synchronized/